%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# 3D Animation
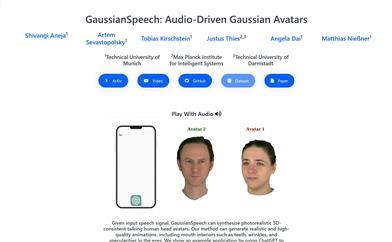
Gaussianspeech
GaussianSpeech is an innovative method capable of synthesizing high-fidelity animated sequences from speech signals to create realistic, personalized 3D head avatars. The technology combines speech signals with 3D Gaussian drawing techniques to capture human head expressions and detailed movements, including skin wrinkling and finer facial motions. Key advantages of GaussianSpeech include real-time rendering speed, natural visual dynamics, and the ability to exhibit a variety of facial expressions and styles. The underlying technology involves the creation of large-scale, multi-view audio-visual sequence datasets and the development of audio conditional transformation models that can directly extract lip and expression features from audio input.
Video Production
48.0K

Vmotionize
Vmotionize is a leading AI animation and 3D animation software capable of transforming videos, music, text, and images into stunning 3D animations. The platform offers advanced AI animation and motion capture tools, making high-quality 3D content and dynamic graphics more accessible. Vmotionize revolutionizes the way independent creators and global brands collaborate, enabling them to bring their ideas to life, share stories, and build virtual worlds through AI and human imagination.
AI video generation
64.9K

Drawingspinup
DrawingSpinUp is an innovative system that converts single character drawings into 3D animations. This technology addresses the challenges of amateur character drawings in appearance and geometry by removing view-dependent outlines and re-rendering along with a skeleton-based refinement deformation algorithm. It not only enhances the visual quality of character drawings but also breathes dynamic life into them, allowing for free rotation, jumping, and even street dance performances.
AI animation generation
51.9K

Animate3d
Animate3D is an innovative framework for generating animations for any static 3D model. Its core ideas include two main parts: 1) Propose a new multi-view video diffusion model (MV-VDM) based on multi-view rendering of static 3D objects and trained on our large-scale multi-view video dataset (MV-Video). 2) Introduce a framework combining reconstruction and 4D score distillation sampling (4D-SDS) that utilizes multi-view video diffusion prior to animate 3D objects. Animate3D enhances spatial and temporal consistency through the design of new spatiotemporal attention modules, and maintains the identity of static 3D models through multi-view rendering. Additionally, Animate3D proposes an effective two-stage process for generating animations for 3D models: First, it directly reconstructs motion from the generated multi-view video, and then refines appearance and motion through the introduced 4D-SDS.
AI video generation
94.7K

SC GS
SC-GS is a novel representation technique that utilizes sparse control points and dense Gaussian functions to represent the motion and appearance of dynamic scenes, respectively. It learns a compact 6-degree-of-freedom (6DOF) transformation basis using a small number of control points, which can be locally interpolated through weight interpolation to obtain a motion field for the 3D Gaussian function. By employing a deformation MLP to predict the time-varying 6DOF transformation for each control point, the method reduces the complexity of learning and enhances its capacity, achieving coherent spatiotemporal motion patterns. Simultaneously, it conjointly learns the 3D Gaussian function, the canonical space positions of the control points, and the deformation MLP to reconstruct the 3D scene's appearance, geometry, and dynamics. During training, the position and number of control points are adaptively adjusted to suit the motion complexity of different regions. A constraint loss function that enforces spatial continuity and local rigidity is also adopted. Thanks to the explicit sparsity of the motion representation and the separation of appearance, this method enables user-controlled motion editing while preserving high-fidelity appearance. Extensive experiments demonstrate that the proposed method outperforms existing approaches in new view synthesis and high-speed rendering, and supports novel applications of user-controlled motion editing with preserved appearance.
AI video generation
51.1K
Move API
_MOVE API is capable of converting videos capturing human motion into 3D animation assets. It supports converting video files to the usdz, usdc, and fbx file formats while offering a preview video. Ideal for integrating into production workflow software, enhancing motion capture capabilities, or creating novel experiences.
AI video editing
125.6K
Synthesizing Moving People With 3D Control
This product is based on a diffusion model framework, designed to generate 3D motion sequences of humans from a single image. Its core components include learning priors about the unseen parts of the human body and clothing, and rendering new body poses with appropriate clothing and textures. We train the model in the texture map space to make it invariant to pose and viewpoint, thus more efficient. Additionally, we develop a diffusion-based rendering pipeline controlled by 3D human poses that produces realistic human renderings. Our method can generate image sequences that align with 3D pose targets while visually resembling the input image. The 3D control also allows for generating various synthetic camera trajectories to render human figures. Experiments demonstrate that our approach can generate image sequences of continuous motion and complex poses, outperforming previous methods.
AI image generation
52.4K
Featured AI Tools

Flow AI
Flow is an AI-driven movie-making tool designed for creators, utilizing Google DeepMind's advanced models to allow users to easily create excellent movie clips, scenes, and stories. The tool provides a seamless creative experience, supporting user-defined assets or generating content within Flow. In terms of pricing, the Google AI Pro and Google AI Ultra plans offer different functionalities suitable for various user needs.
Video Production
43.1K

Nocode
NoCode is a platform that requires no programming experience, allowing users to quickly generate applications by describing their ideas in natural language, aiming to lower development barriers so more people can realize their ideas. The platform provides real-time previews and one-click deployment features, making it very suitable for non-technical users to turn their ideas into reality.
Development Platform
46.1K

Listenhub
ListenHub is a lightweight AI podcast generation tool that supports both Chinese and English. Based on cutting-edge AI technology, it can quickly generate podcast content of interest to users. Its main advantages include natural dialogue and ultra-realistic voice effects, allowing users to enjoy high-quality auditory experiences anytime and anywhere. ListenHub not only improves the speed of content generation but also offers compatibility with mobile devices, making it convenient for users to use in different settings. The product is positioned as an efficient information acquisition tool, suitable for the needs of a wide range of listeners.
AI
43.6K

Minimax Agent
MiniMax Agent is an intelligent AI companion that adopts the latest multimodal technology. The MCP multi-agent collaboration enables AI teams to efficiently solve complex problems. It provides features such as instant answers, visual analysis, and voice interaction, which can increase productivity by 10 times.
Multimodal technology
45.3K
Chinese Picks

Tencent Hunyuan Image 2.0
Tencent Hunyuan Image 2.0 is Tencent's latest released AI image generation model, significantly improving generation speed and image quality. With a super-high compression ratio codec and new diffusion architecture, image generation speed can reach milliseconds, avoiding the waiting time of traditional generation. At the same time, the model improves the realism and detail representation of images through the combination of reinforcement learning algorithms and human aesthetic knowledge, suitable for professional users such as designers and creators.
Image Generation
44.2K

Openmemory MCP
OpenMemory is an open-source personal memory layer that provides private, portable memory management for large language models (LLMs). It ensures users have full control over their data, maintaining its security when building AI applications. This project supports Docker, Python, and Node.js, making it suitable for developers seeking personalized AI experiences. OpenMemory is particularly suited for users who wish to use AI without revealing personal information.
open source
43.9K

Fastvlm
FastVLM is an efficient visual encoding model designed specifically for visual language models. It uses the innovative FastViTHD hybrid visual encoder to reduce the time required for encoding high-resolution images and the number of output tokens, resulting in excellent performance in both speed and accuracy. FastVLM is primarily positioned to provide developers with powerful visual language processing capabilities, applicable to various scenarios, particularly performing excellently on mobile devices that require rapid response.
Image Processing
42.0K
Chinese Picks

Liblibai
LiblibAI is a leading Chinese AI creative platform offering powerful AI creative tools to help creators bring their imagination to life. The platform provides a vast library of free AI creative models, allowing users to search and utilize these models for image, text, and audio creations. Users can also train their own AI models on the platform. Focused on the diverse needs of creators, LiblibAI is committed to creating inclusive conditions and serving the creative industry, ensuring that everyone can enjoy the joy of creation.
AI Model
6.9M